 |
| Trainingsausgabe Ocropus 0.7 |
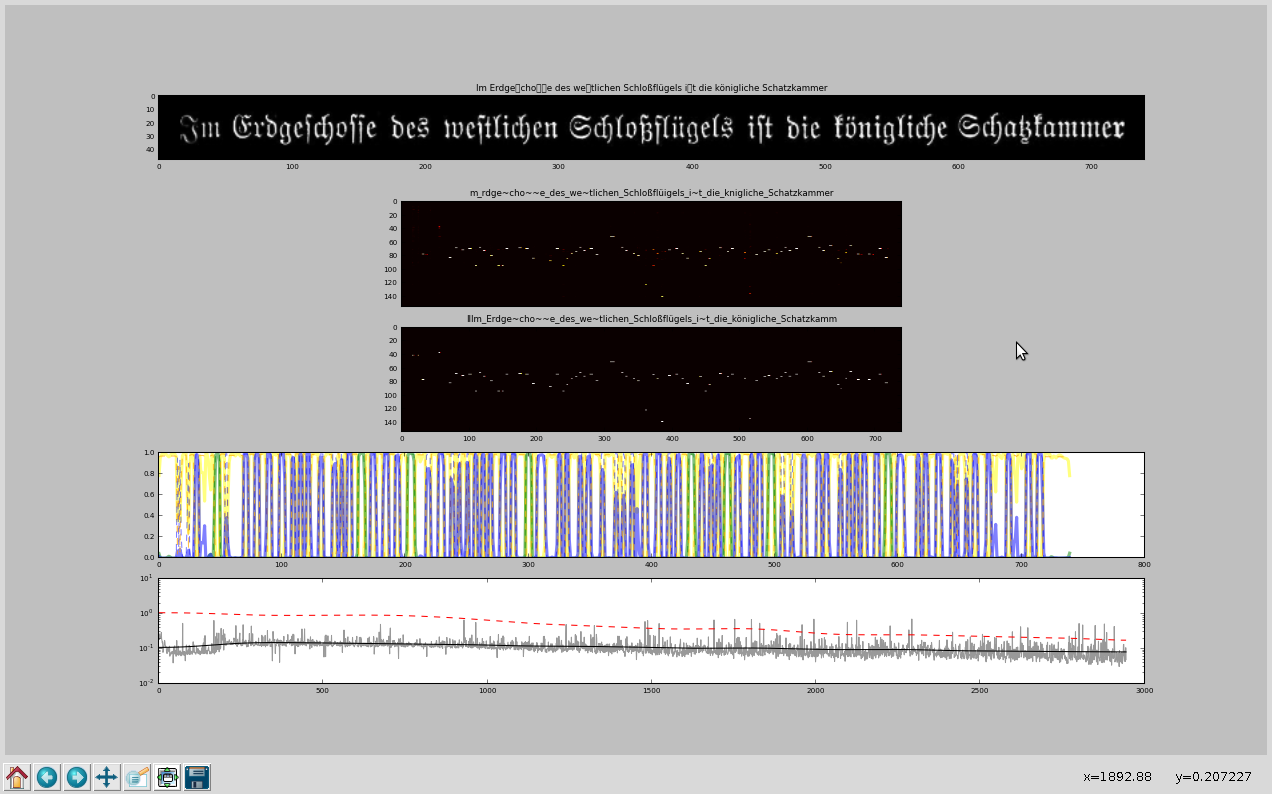
Im letzten Beitrag hatte ich einen ersten Vergleich zwischen Ocropus 0.7 und Tesseract 3.02 gezogen. Da leider die mitgelieferten Dateien für Fraktur keine Unterstützung für das lange-S beinhalten, muß ich Ocropus selber trainieren.
Unterschied Tesseract- und Ocropus Trainingsdaten
Leider hat sich bei Ocropus 0.7 der Trainingsmodus geändert. Um die gleichen Dateien, wie Tesseract 3.02 zu verwenden, habe ich ein Script geschrieben, welches die Tesseract-Boxfiles und zugehörige TIFF-Dateien so umwandelt, daß die von Ocropus erwarteten zeilenbasierten PNG-Dateien mit zugehörigen Text-Dateien erzeugt werden.
Aus dem tess_train Verzeichnis:
tess_train ├── bigram_words ├── deu-frak.bigram-dawg ├── deu-frak.config ├── deu-frak.frak2.exp0.box ├── deu-frak.frak2.exp0.tif ├── deu-frak.frak2.exp0.tr ├── deu-frak.frak2.exp0.txt : ├── deu-frak.frak2.exp9.box ├── deu-frak.frak2.exp9.tif ├── deu-frak.frak2.exp9.tr ├── deu-frak.frak2.exp9.txt ├── deu-frak.freq-dawg ├── deu-frak.inttemp ├── deu-frak.normproto ├── deu-frak.number-dawg ├── deu-frak.pffmtable ├── deu-frak.punc-dawg ├── deu-frak.shapetable ├── deu-frak.traineddata ├── deu-frak.unicharambigs ├── deu-frak.unicharset ├── deu-frak.word-dawg ├── font_properties ├── freq ├── get_bigramword_list.pl ├── get_freqlist.pl ├── get_wordlist.pl ├── number ├── ogerman ├── punc ├── train.sh ├── unicharset └── unicharset.edited