 |
| Trainingsausgabe Ocropus 0.7 |
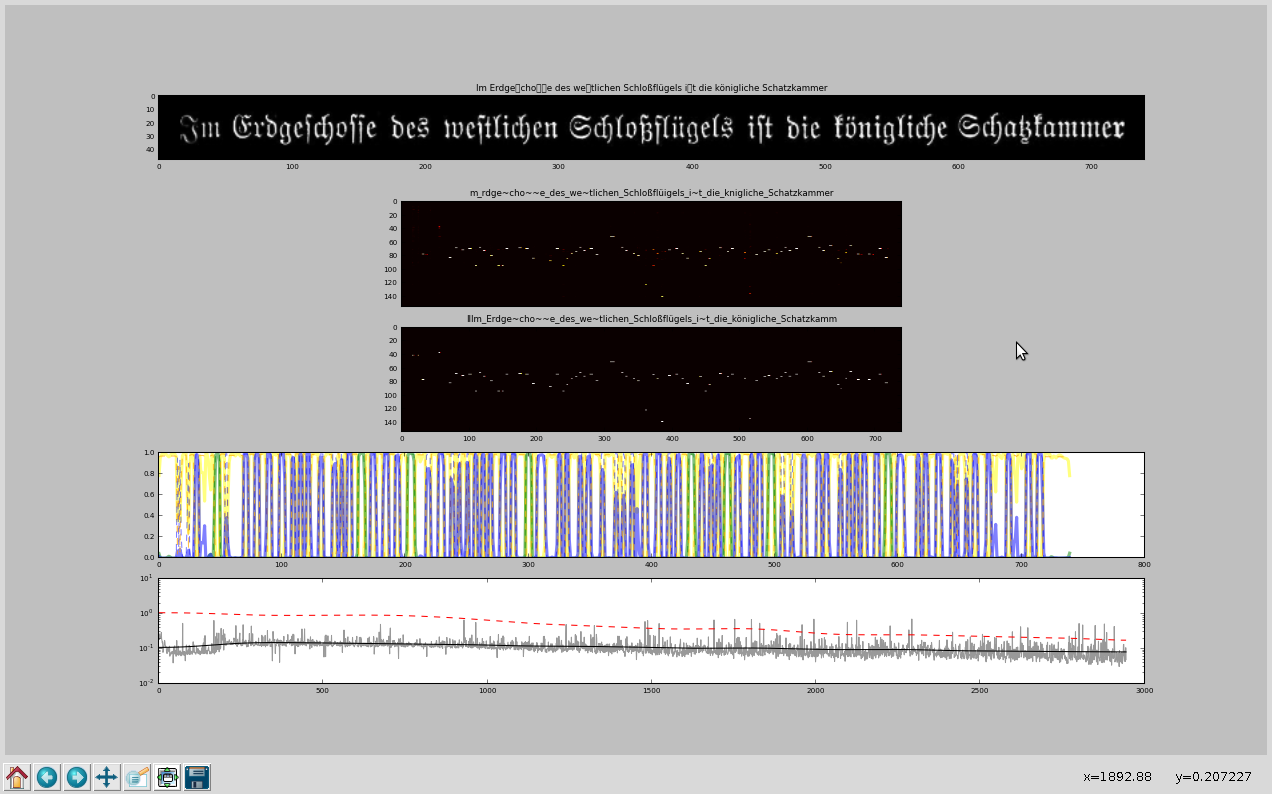
Im letzten Beitrag hatte ich einen ersten Vergleich zwischen Ocropus 0.7 und Tesseract 3.02 gezogen. Da leider die mitgelieferten Dateien für Fraktur keine Unterstützung für das lange-S beinhalten, muß ich Ocropus selber trainieren.
Unterschied Tesseract- und Ocropus Trainingsdaten
Leider hat sich bei Ocropus 0.7 der Trainingsmodus geändert. Um die gleichen Dateien, wie Tesseract 3.02 zu verwenden, habe ich ein Script geschrieben, welches die Tesseract-Boxfiles und zugehörige TIFF-Dateien so umwandelt, daß die von Ocropus erwarteten zeilenbasierten PNG-Dateien mit zugehörigen Text-Dateien erzeugt werden.
Aus dem tess_train Verzeichnis:
tess_train ├── bigram_words ├── deu-frak.bigram-dawg ├── deu-frak.config ├── deu-frak.frak2.exp0.box ├── deu-frak.frak2.exp0.tif ├── deu-frak.frak2.exp0.tr ├── deu-frak.frak2.exp0.txt : ├── deu-frak.frak2.exp9.box ├── deu-frak.frak2.exp9.tif ├── deu-frak.frak2.exp9.tr ├── deu-frak.frak2.exp9.txt ├── deu-frak.freq-dawg ├── deu-frak.inttemp ├── deu-frak.normproto ├── deu-frak.number-dawg ├── deu-frak.pffmtable ├── deu-frak.punc-dawg ├── deu-frak.shapetable ├── deu-frak.traineddata ├── deu-frak.unicharambigs ├── deu-frak.unicharset ├── deu-frak.word-dawg ├── font_properties ├── freq ├── get_bigramword_list.pl ├── get_freqlist.pl ├── get_wordlist.pl ├── number ├── ogerman ├── punc ├── train.sh ├── unicharset └── unicharset.editedwird das ocropus_train Verzeichnis:
├── ocropus │ └─── deu-frak.frak2.exp0
│ │ ├── 010000.bin.png │ │ ├── 010000.gt.txt │ │ ├── 010001.bin.png │ │ ├── 010001.gt.txt │ │ ├── 010002.bin.png │ │ ├── 010002.gt.txt : : : │ │ ├── 010009.bin.png │ │ ├── 010009.gt.txt │ │ ├── 01000a.bin.png │ │ ├── 01000a.gt.txt │ │ ├── 01000b.bin.png │ │ ├── 01000b.gt.txt : : : │ │ ├── 01000e.bin.png │ │ └── 01000e.gt.txt : : ├── ocropus_train.sh └── tess2ocropus.sh
Script
Und hier das Script:
#!/bin/bash
# script to use tesseract 3.02 training files to generate ocropus 0.7 training files
# created 2013 by Andreas Romeyke (art1@andreas-romeyke.de)
# should be used under terms of Gnu General Public License v3.0 or higher
# see http://www.gnu.org/licenses/gpl-3.0.html for LICENSE and further information
#
# needs an installed imagemagick
#
# call: tess2ocropus tess_train/ ocrotrain/
function convert_page {
pagefname=$1;
gap=9; # to recognize spaces between text
echo $pagefname
# read file
# extract line from tiff
# write png and assoc text
lastx=0
lastx1=0
lasty=0
maxx=0
minx=100000
maxy=0
miny=100000
IFS=$'\n'
let lineno=0;
dimy=0;
# calc max dimy, needed to calc offset correctly
for line in $(cat $pagefname); do
y1=$(echo $line | cut -d " " -f 5)
if [ $y1 -gt $dimy ]; then dimy=$y1; fi
done
srcimage=$tessdir/$(basename $pagefname ".box").tif
tmpimage=$(basename $pagefname ".box").png
convert -flip $srcimage $tmpimage
mkdir $ocropusdir/$(basename $pagefname ".box");
for line in $(cat $pagefname); do
c=$(echo $line | cut -d " " -f 1)
x0=$(echo $line | cut -d " " -f 2)
y0=$(echo $line | cut -d " " -f 3)
x1=$(echo $line | cut -d " " -f 4)
y1=$(echo $line | cut -d " " -f 5)
let w=1+$maxx-$minx;
let h=1+$maxy-$miny;
if [ $x0 -lt $lastx ]; then
# extract
# width height offsetx offsety
let ox=$minx;
let oy=$miny; #$dimy-$maxy;
slineno=$(printf "01%04x" $lineno)
tgtimage=$ocropusdir/$(basename $pagefname ".box")/$slineno.bin.png
tgttxt=$ocropusdir/$(basename $pagefname ".box")/$slineno.gt.txt
echo "extract new line: ${w}x$h+$ox+$oy ($minx $miny $maxx $maxy) dimy=$dimy word=$word"
convert -extract ${w}x$h+$ox+$oy $tmpimage -flip $tgtimage
echo "$word" >$tgttxt
let lineno=$[lineno+1];
maxx=$x1
minx=$x0
maxy=$y1
miny=$y0
word=""
else
if [ $x0 -lt $minx ]; then minx=$x0; fi
if [ $x1 -gt $maxx ]; then maxx=$x1; fi
if [ $y0 -lt $miny ]; then miny=$y0; fi
if [ $y1 -gt $maxy ]; then maxy=$y1; fi
fi
let dx=$x0-$lastx1;
if [ $dx -gt $gap ]; then word="${word} "; fi
word="${word}${c}"
lastx=$x0
lastx1=$x1
lasty=$y0
done
# extract
# width height offsetx offsety
let ox=$minx;
let oy=$miny; #$dimy-$maxy;
slineno=$(printf "01%04x" $lineno)
tgtimage=$ocropusdir/$(basename $pagefname ".box")/$slineno.bin.png
tgttxt=$ocropusdir/$(basename $pagefname ".box")/$slineno.gt.txt
echo "extract new line: ${w}x$h+$ox+$oy ($minx $miny $maxx $maxy) dimy=$dimy word=$word"
convert -extract ${w}x$h+$ox+$oy $tmpimage -flip $tgtimage
echo "$word" >$tgttxt
unset IFS
unset word
rm -f $tmpimage
}
tessdir=$1
ocropusdir=$2
if [ -e "$tessdir" ]; then
if [ -e "$ocropusdir" ]; then
# here convert
# for each *.box
for file in $tessdir/*.box; do
convert_page $file
done
else
echo "no ocropusdir given '$ocropusdir'"
fi
else
echo "nop tessdir given '$tessdir'"
fi
Unterstützung für langes-S patchen
Leider fehlt in der Datei ' ocropus/ocropy/ocrolib/chars.py' in der Zeile 6 das lange-S:letters = u"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
und muß wie folgt ergänzt werden:
letters = u"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzſ"
Dies schaltet die Unterstützung für das lange-S ein.
Um nun Ocropus zu trainieren, genügt dann ff. Aufruf:
ocropus-rtrain 'ocropus/*/*.bin.png' -F 30 -d 1 -o bbads_fraktur